 Archive.org гордо и по праву именует себя «Архивом интернета», и с далекого 1996 года парсит всю сеть с целью архивации и структурирования данных. Этот сайт прямо или косвенно может принести пользу и нам. По данным Википедии, на октябрь 2012 года, Архив содержал данные о более чем 85 миллиардах страниц, а общий объем всех архивированных данных превышает 10 петабайт. Здесь хранится история Интернета в целом и интернет — бизнеса в частности.
Archive.org гордо и по праву именует себя «Архивом интернета», и с далекого 1996 года парсит всю сеть с целью архивации и структурирования данных. Этот сайт прямо или косвенно может принести пользу и нам. По данным Википедии, на октябрь 2012 года, Архив содержал данные о более чем 85 миллиардах страниц, а общий объем всех архивированных данных превышает 10 петабайт. Здесь хранится история Интернета в целом и интернет — бизнеса в частности.
Благодаря своей старой истории и общественно-социальной деятельности Archive.org является одним из самых трастовых сайтов интернета. Об этом можно судить по некоторым показателям:
1. Возраст сайта — почти 20 лет (Registered On — December 14, 1995).
2. Google PR – 8 (Яндекс ТИЦ – 5200).
3. Большое количество проиндексированных страниц (~70 миллионов).
4. Данный ресурс входит в 250 самых посещяемых сайтов мира (согласно данным Alexa.com).
Archive.org может стать полезным для каждого вебмастера, если научиться его использовать в своих целях. Исходя из всего написанного, можно сделать вывод, что Архив довольно трастовая площадка для получения линков и создания доров. Также ее можно использовать по своему основному направлению, ведь это огромный ресурс для получения различного контента.
Начнем с самой интересной и актуальной на сегодняшний день темы – создание доров на сайте Archive.org. В Google вы без проблем найдете много примеров классических «профильных» доров на Archive .org по различным НЧ ключевым фарма – словам (для примера запрос Buy Tadalafil Prescription Supplement Cost – проверка по aol.com):
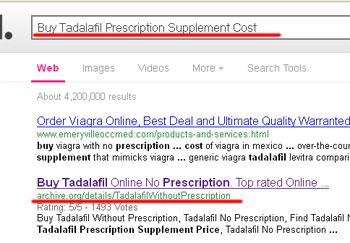
Конкретный дор использует картиночный фид от PPC, но рекомендуется делать красивые перенаправления на свои фарма шопы. Рассмотрим в общих чертах процедуру создания дора. Для начала нужно создать аккаунт. Для этого следует перейти по ссылке https://archive.org/account/login.createaccount.php и заполнить все поля:
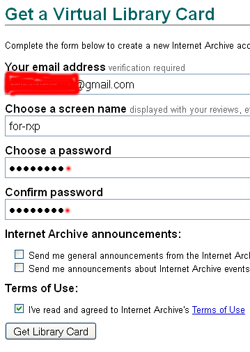
«Screen name» особой роли не играет, url будущего дора вы будете формировать самостоятельно. Email нужно указывать реальный, а регистрацию аккаунта необходимо подтвердить. Проходят вариации в адресе Gmail (для вашего ящика login@gmail.com, вы можете использовать безграничное количество вариаций, добавляя раномные символы со знаком +: login+1@gmail.com, login+rxpthebest@gmail.com, и вся почта будет приходит в ваш ящик). Многие сервисы не принимают такой формат, заставляя регистрировать много новых ящиков. Но Archive.org пока не ввел дополнительную защиту.
Для того, чтобы создать дор по адресу http://archive.org/details/DOR необходимо залить какой-либо файл и в его описание уже вставить все, что вам необходимо. После логина вы сразу увидите синюю кнопку «Upload» в правом углу и, перейдя по ней, форму загрузки:
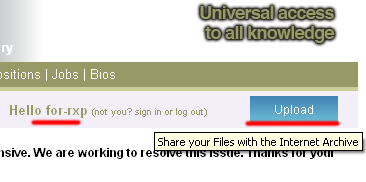
Заливать можно как html с тем же дором (но он не проиндексируется), так и просто какой-либо PDF на тему здоровья. Выбираем файл, нажимаем загрузить и попадаем в редактор:
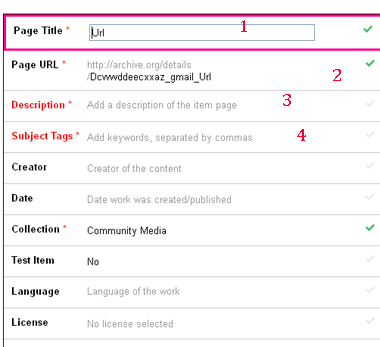
Основные моменты:
1. Page title – тайтл страницы и будущего дора. Заполняется согласно целям.
2. Page url – часть адреса дора после /details/
3. Description – сам контент дора. Картинка для входа, кеи, текст и т.д.
4. Subject Tags – не очень важно, но помогает для того, чтобы дор был в поиске по Архиву, что гарантирует более быстрый индекс.
В результате чего получаем такой пример — https://archive.org/details/rxpssssssz. В некоторых случаях редактор может удалить ссылку, но есть возможность вставить ее обратно, нажав на Edit items (чтобы не удаляло, пишите изначально в формате a href=http://google.com – т.е. без кавычек после =).
Каждый сам может подобрать необходимую схему создания и заливки доров. Добавляйте текст, кеи и эксперементируйте с оформлением. На странице https://archive.org/details/opensource_media выводятся последние обновления и комментарии (очень медленно и непонятно), но на всяких случай, чтобы ускорить индексацию, напишите себе 1-2 обзора, так вы попадете в Recently Reviewed Items.
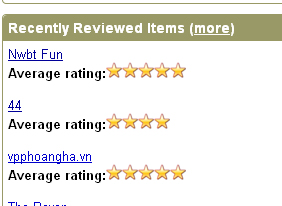
Эти же обзоры (Reviews) помогут получить звездочки в сниппетах Googla, что повысит внимание в выдаче к дору:
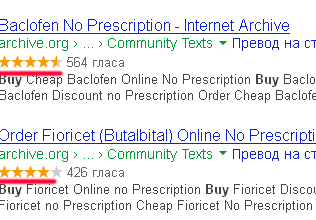
Что дальше делать с дорами вы знаете. Аналогично можно использовать данные профиля для получения ссылочной массы. Правда везде будет Nofollow, о полезности которого ведутся постоянные споры. Но ссылка со столь трастового ресурса никогда не помешает.
Если вы все же решите ее получить, залейте какой-нибудь PDF файл с отчетом о последней конференции по лечению импотенции себе на сайт. Такой же залейте в archive.org, а в описании источника укажите, что вы нашли его именно на своем сайте. Это обеспечит практически вечную ссылку. За деятельностью «коллег по цеху» вы можете наблюдать благодаря внутреннему поиску. http://archive.org/search.php?query=subject%3A%22viagra%22:
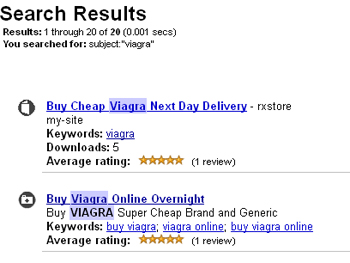
Перейдем к следующему сервису от Archive.org , а именно — Web.Archive или WayBack Machine. Поисковые роботы данного сервиса обходят сайты и архивируют их на своих серверах, создавая копии для истории. Естественно, что сайты довольно часто перестают существовать, и копии в web архиве остаются единственным напоминанием о них.
Данные сайты можно восстанавливать и использовать для своих нужд. Можно использовать их как сателлиты, как площадки для ссылок на свои ресурсы или продажу, можно монетизировать с помощью Adsense или партнерских программ. Для начала необходимо определится с тем, какой именно сайт восстанавливать. Это довольно сложный вопрос и существуют несколько основных вариантов его решения:
1. Поиск информации на тематических площадках по продаже доменов. Перехватчики часто продают освобожденные домены с указанием того, есть или нет копия сайта в Web.Archive. Вы можете как купить домен и восстановить прежний сайт, так и просто узнать, какой сайт можно восстановить на новом домене, загнав его в индекс быстрее, чем это сделает потенциальный покупатель домена. Основной русскоязычной площадкой для покупки/продажи доменов является – доменфорум, смотрите также и на тематических форумах для вебмастеров.
2. Сбор данных об освободившихся доменах самостоятельно.
3. Покупка доменов на аукционах или просто использование информации с них. Подробно описано в хорошей статье https://www.rxpblog.com/work-with-auctions-buying-trusted-domains здесь.
Ну и конечно, если вы плотно работает в какой либо теме, вы прекрасно знаете своих конкурентов, их сателлиты и другие места, которые в случае краха можно восстановить для своих целей. Результаты наличия в Архиве доступны по адресу http://web.archive.org/web/*/http://rxpblog.com:
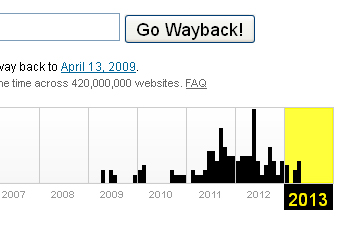
После того как мы определились ЧТО восстанавливать, понадобятся инструменты для этого. Когда домен и его наличие в Веб.Архиве являются известными факторами, можно сразу приступать к восстановлению. Но в случае, если вы используете списки удаленных доменов, первоначально необходимо проверить есть ли история для них в Архиве. Получить списки таких доменов можно различными способами: существует огромное количество online сервисов для deleted domains, как платных, так и бесплатных, чекеров и программ.
Рассмотрим пример, как это делать с помощью «Определяйки» (официальный сайт программы — http://netpeak.ua/soft/opredelyayka/). После установки и запуска вам предложат список опций, по которым она будет проверять домены:
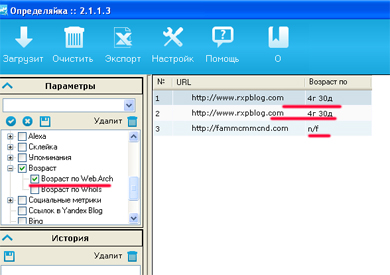
Отмечаем чекбокс – Возраст по Web.Archive, нажимаем кнопку «Загрузить», и если у сайта есть история в архиве, вы получите его возраст там, если нет – значение n/f. Потом делаете экспорт в файл Exel, сортируете и выбираете необходимые для работы данные.
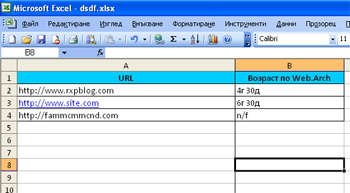
Теперь есть список свободных доменов, которые могут быть перехвачены киберсквотерами. Но это не страшно, ведь в 90% случаев, если не больше, эти люди вешают домены на парковку или страницу продажи, абсолютно не интересуясь контентом из прошлой жизни сайтов с существующей историей в Архиве.
Для парсинга результатов Архива и их локального сохранения существует много различного софта, и выбор зависит исключительно от вас. Поиск нужно делать по термину — Web Archive Downloader / graber / parser. Рассмотрим процесс работы на примере довольно дешевого варианта — Web Archive Downloader . Качаем, покупаем ключ и запускаем (без ключа можно сохранять по 20 страниц с сайта). Выбираете года, которые интересуют:
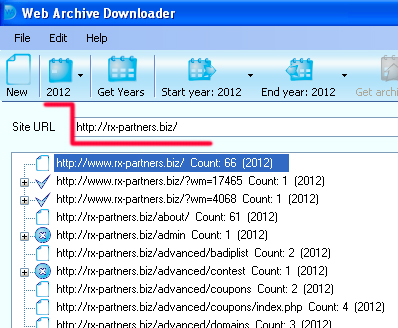
Вставляете URL и нажимаете Get Url List:
Спустя N минут загрузится список доступных страниц. После этого нажимаете «Download» и начнется загрузка сайта на ваш хард-диск. Дальше сайт придется привести к товарному виду: поменять пути, поправить картинки и т.д., если автоматически этого сделать не удалось. Конечно, вы можете сделать тоже самое различными программами из категории Offline Explorer или найти более удачное ПО. Кроме извлечения сайта можно и просто брать текстовый контент для последующего применения. Статьи являются уникальными для поисковых систем и их можно смело использовать для наполнения своих сайтов и сателлитов.
Как же еще можно применить архив сайта в работе? Archive.org — это огромный архив текстовой и медиа информации. Например, можно парсить книги, статьи и другой текстовый материал для последующей обработки и генерации в дорвейных технологиях или сплогах. Вбиваете в поиск, например, health и получаете список публикаций о здоровье:
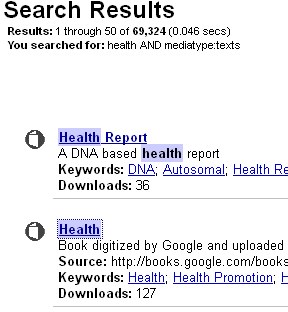
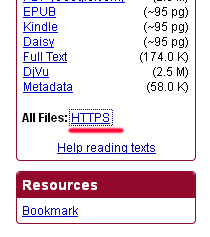
Практически у каждого результата будут варианты в .txt файле, которые легко сохранять и парсить для последующего использования. Чтобы добраться до файла в этом формате, необходимо нажать на HTTPS линк напротив All files&.
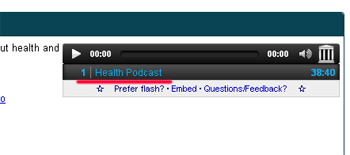
Кроме текстовой информации данный ресурс складирует и различные аудио и видео записи, которые тоже могут пригодиться для некоторых блогов и сайтов. Если вбить в поиск запрос health AND mediatype:audio, можно получить подкасты и различные записи с радиостанций на тему здоровья.
Или health AND mediatype:movies и получить ролики на тему здоровья. Правильное их использование может сильно повысить поведенческие факторы на ваших ресурсах.
Вот и все. Надеюсь, что каждый из вас по-новому откроет для себя этот чудесный сайт, а данная статья хоть чуть-чуть поможет в нашем нелегком деле. 🙂
Автор статьи: LoNduk.
