 Google методично за последние годы благодаря самообучаемому искусственному интеллекту трансформировал органическую выдачу в поисковик в котором на всех ключевых позициях размещены различные маркетплейсы, новостники-агрегаторы и партнерские сайты напрямую приобретшие рекламу в Google ADS и в этом не последнюю роль сыграли именно сущности (взаимосвязи) графа знаний.
Google методично за последние годы благодаря самообучаемому искусственному интеллекту трансформировал органическую выдачу в поисковик в котором на всех ключевых позициях размещены различные маркетплейсы, новостники-агрегаторы и партнерские сайты напрямую приобретшие рекламу в Google ADS и в этом не последнюю роль сыграли именно сущности (взаимосвязи) графа знаний.
Для поисковика эти сайты заслуживают большее доверие на общем фоне некачественного контента, в том числе нахлынувшей потенциальной дезинформации, ведь по многочисленным мнениям ассесоров топовые сайты целиком и полностью удовлетворяют интентам (целевым запросам) пользователей, поэтому по мнению представителей компании Google SEO продвижением можно пренебречь или вовсе отказаться, сделав его затяжным и ресурсоемким. Но не всё так критично, ведь есть хитрые лазейки, через которые по-прежнему можно форсировать некоторые факторы ранжирования в продвижении сайтов. Если вернуться к сущностям графа знаний Google, то те, кто помнит была такая новомодная фича, которая давала возможность через разметку веб-страницы демонстрировать поисковому боту путём прямого оглавления всех своих социальных профилей в каждой отдельно взятой соцсети: Facebook, Twitter, Google+ и т.д. За это отвечал атрибут – SameAs:
- URL = URL of our domain
- sameas = social of the business we’re listing
но с прошедшей осени 2021 года Google отменил этот параметр, хотя сам данный граф до сих пор используется многими вебмастерами для своих money-сайтов, надеющихся на положительный эффект. Как бы то ни было, этот идентификатор мне интересен тем, что благодаря ему можно проводить OSINT разведку, то есть выявлять все связи той или иной личности в соцсетях, при этом надо ещё дополнительно учесть, что соцсеть Google+ официально прекратила свою работу 2 апреля 2019 года! А вот атавизмы самой соцсети в виде логотипов, упоминаний никнеймов Google+ в подписях профилей, а также в сущностях графа знаний по-прежнему встречаются особенно среди тех сайтов, которые были восстановлены из Web Archive, но сейчас не об этом – это пиша для асинхронного размышления на будущее. А в данный момент, как говорится картина маслом сама соцсеть Google+ уже как три года канула в историю, а на её связи до сих пор продолжаешь натыкаться. Это мне дало толчок к генерации востребованных профилей авторов, как раз за это отвечает алгоритм Google EAT, который акцентируется на авторитетных экспертах в том или ином секторе контент-маркетинга, попутно выявляющего все связи авторов, чтоб реально установить их степень профессиональной компетенции, особенно, когда речь идёт об YMYL-сайтах на которых они являются штатными компиляторами контента.
Как же возможны манипуляции с профилированием личностей? Ни для кого не секрет, что в Интернете создать цифровую фейковую личность (дропа) — это пара кликов мышки; цифрового двойника (аватара) сфабриковать уже немного сложнее, ведь необходимы оригинальные фотографии, персональные и контактные данные, но и это тоже всё решаемо через определенного рода сервисы. Но мне не понадобится ни то не другое, просто буду брать то, от чего сами «эксперты» отказались, но именно благодаря их перечню профессиональных качеств, авторитетности и известности, я смогу получить определенные преференции со стороны поисковой системы, которые обычными методами просто не достижимы в кратчайшие сроки и с наскока форсировать не получится, а в долгую это не так заманчиво.
Найти аккаунт Google Plus проще-простого, если знаете конкретный адрес от электронной почты Gmail или идентификатор Google ID. Сама соцсеть Google Plus оставила весьма обширный след в электронном мире, поэтому до сих пор сохранились фотографии, посты, перекрестные ссылки на прочие социальные сети, метаописания, имена пользователей Google. Всё это по умолчанию закэшировано в Web Archive, где сохранились сотни миллионов профилей, к которым открыт доступ всё по тем же параметрам, которые перечислены выше: по адресу почты Gmail или Google ID. Переходим к практике, для этого понадобится установленный мессенджер Telegram (кроссплатформенная система мгновенного обмена сообщениями с функциями VoIP). Далее в строке поиска задаем параметр: @UniversalSearchBot. Этот автобот позволяет в бесплатном режиме проводить OSINT разведку, которая с открытых источников на основе искомого email-адреса получает практически все известные сущности графа знаний того или иного пользователя сервисами Google в том числе закрытой на данный момент социальной сетью Google+:
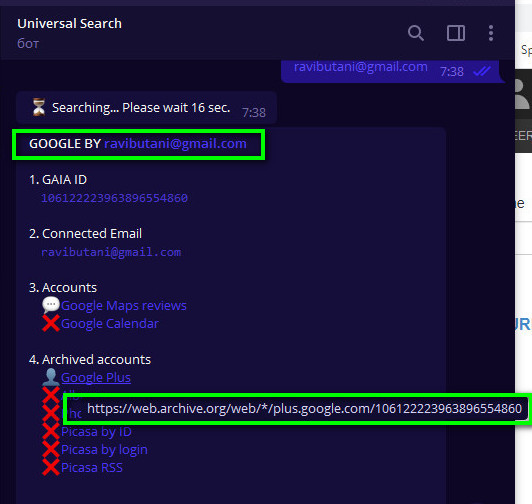
Как можете увидеть, Телеграм-бот успешно нашёл преизбыточную информацию и на её базе создал репрезентативный профиль пользователя, в том числе и ссылку на копию страницы Google+ в Web Archive. Стоит учесть, что если email-адрес будет с датой регистрации после сентября 2021 года, то как следствие никакой информации по Google+ в отчете автобота не будет. Относительно самих профилей в Web Archive, то многие из них, которые представляют обычные веб-страницы могут не отображать визуально графики, но стоит открыть исходный код или в инструментах разработчика перейти в раздел Applications, то там можно увидеть сохраненные URL-адреса на изображения, биометрические характеристики, текстовые комментарии и другие данные аккаунта. Всё это может пригодится, например для создания фейковых персон определённого пользователя в тех соцсетях, в которых он не успел зарегистрироваться, разумеется, с размещёнными обратными ссылками на свои личные проекты.
Как вы все помните Google+ в основном использовали для накрутки социальных сигналов, поэтому многие профили имели огромное количество входящих и исходящих ссылок, это очень прекрасно можно было видеть через любой анализатор входящих/исходящих ссылок. Я же воспользовалась паблик базой, которая на январь 2022 года содержала листинг профилей Google+ в размере более одного миллиона, да это не вся база пользователей соцсети, но и не капля в море. Возможно другие источники профилей Google+ вы найдёте самостоятельно. Стоит учесть, что среди никнеймов пользователей встречаются крупные известные бренды, которые автоматически уже не подходят, а также персоны нулевки с отсутствием ссылочного, тоже отсеиваем. А вот многочисленные профили, содержащие в своём названии имя и фамилию владельца, как показала практика привязки к своим личным зарегистрированным доменным именам, не имеют, но зато у этих аккаунтов в наличии добротная прокачка ссылочного окружения. Поэтому, если зарегистрировать такой домен и далее на самом сайте обозначить авторство контента от донорского имени и фамилии, то, по сути, я получаю готового эксперта с уже определенным трастом в Google, который был унаследован от Google+. Если алгоритм понятен, то я продемонстрирую этот процесс на отдельно взятом примере. На западе широко распространено употреблять имя и фамилию, поэтому портфолио аккаунтов выглядит обычно так:
- Google+ Account ID: +ArlinaFitriyaniDee
- Google Adsense profile: pub-1556223355139109
- Website address in use since: 12-Mar-01
- Day of domain address Expiration: 18-Mar-01
- Last modified: 17-Mar-20
Для примера выбрала, вот этот профиль — +ArlinaFitriyaniDee:
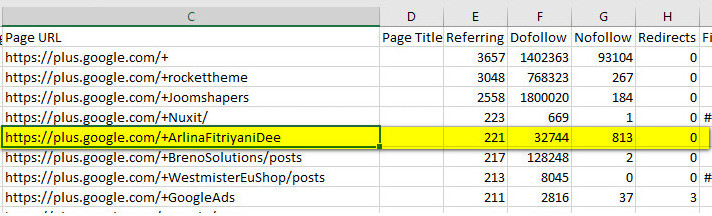
На первый взгляд это очень перспективный профиль почти тридцать три тысячи ссылок (увы сейчас уже все это кануло в историю), но всё же стоит детально изучить персону, что про неё знает Google на данный момент времени, ведь именно благодаря ссылкам и многочисленным упоминаниям в сети персонам присваивается статус графа знаний:
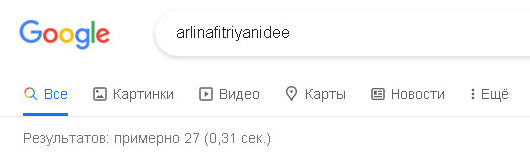
Всего лишь двадцать семь результатов поиска, да и самой дополнительной панели графа знаний нет, но не суть, самое приятное, как выше отмечено по этому псевдониму – arlinafitriyanidee, нет зарегистрированного домена верхнего уровня (TLD) в зоне .COM:
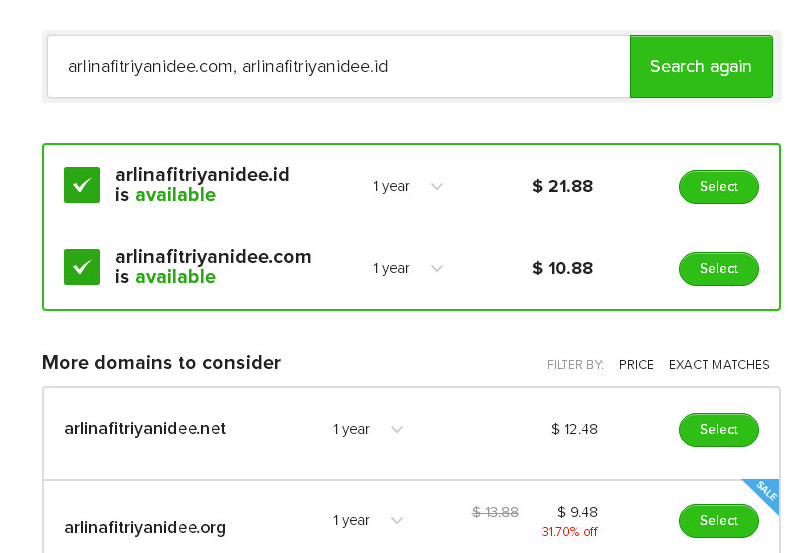
Это только пример, мне, как и вам конечно очевидно, что сама Арлина Фитриади не специалист, не авторитет и т.д. Здесь надо отметить, что поиск персон не так сложен и с ним справится любой, поэтому профессиональных авторов — специалистов своего дела вам предстоит разыскивать самостоятельно, ведь у каждого из вас свои персональные предпочтения и видения для выстраивания архитектуры сущностей графа знаний Google. Очевидный плюс таких доменных имён в том, что это не бренд, не торговая марка, так что претензии, если будут со стороны доноров профилей Google+, то их можно с легкостью обойти, отписавшись, что мол надо же какое совпадение не только нашёлся однофамилец, но и имя совпадает…А поисковик несмотря на свой искусственный интеллект с большим трудом отличит персону двойника или вообще фейка, точных параметров на этот счёт нет даже в алгоритме HILLTOP (алгоритм определяющий качество и соответствие сайта ключевым запросам на основании мнения сайтов экспертов в этой области, которые обратными ссылками рекомендуют ваш сайт, как заслуживающий для обязательного ознакомления).
Больше скажу, есть прямое обратное подтверждение регулярными жалобами вебмастеров о том, как их контент был растиражирован дорвейщиками, так что в конечном итоге копипаст ранжируется в органике выше, чем авторские экземпляры (исходники). Структура графа знаний будет просто пересмотрена и обновлена сущность отдельно взятого пользователя, а также его связь с новым релевантным зарегистрированным доменным именем. Сам же домен при очередном обновлении графа знаний при наличии связи с персоной донора имеющей сущность получит определённый коэффициент надежности и доверия со стороны поисковика, тем более на сам домен будет положительно влиять то что Google будет рекомендовать этот сайт с конкретным доменным именем, каждый раз, когда будет в поиске сформирован пользователями запрос, полностью совпадающий с доменом верхнего уровня, предлагая им на выбор альтернативную поисковую выдачу с такой фразой: «Возможно, вы имели ввиду: …»
Google+ это не единственный источник для поиска донорских профилей авторов, соцсетей большое изобилие, но самые лакомые это заброшенные профили с датами регистрации от 1990-х по 2000-е года. Надеюсь вам, понравилась данная модель профилирования сайтов брошенными аккаунтами Google+.
Автор статьи: Lesy.